TOPICS
トピックス

OpenAIのAPIを活用した生成AIプロダクト開発 – 経営者・事業責任者のためのガイド
2023.12.19 / COLUMN
OpenAIのAPIを活用した生成AIプロダクト開発 – 経営者・事業責任者のためのガイド
1. はじめに
この記事の目的は、OpenAIのAPIを活用して新しいビジネス機会を探求しようと考えている日本企業の経営者や新規事業担当者向けに、生成AI技術、特にChatGPTとその周辺技術のビジネスへの応用に関する理解を深め、具体的な活用方法を提供することにあります。本記事では、技術的な複雑さに立ち入ることなく、ビジネスリーダーが直面する課題や機会を中心に議論を進めていきたいと思います。
1.1 ChatGPTと生成AIの現在の動向
2022年11月30日にChatGPTが公開されて以来、ビジネス世界は顕著な変化を遂げています。この革新的な自然言語処理(NLP)技術は、企業の社内プロセスを最適化したり、企業が顧客との対話を強化したりする新たな方法を提供しました。2023年、特に目立つのは、ChatGPTを中心とした生成AIプロダクト開発の活発化です。このトレンドは、ビジネスコミュニケーション、顧客サービス、製品開発など多岐にわたる領域に影響を及ぼしています。
企業のChatGPTを活用した開発事例としては、文章の要約や翻訳、アイデア出しなど社内の日常業務をセキュアに効率化することを目的に三井不動産株式会社が開発をした「&Chat」や、法律相談に対してAIが自動的に相談対応することを目的に弁護士ドットコムが開発した「チャット法律相談(α版)」、また、求職者向けに小さな負荷で最適な内容の職務経歴書を作成できる「GPTモデルのレジュメ自動作成機能」や採用企業向けに求人/募集要項を自動作成する「GPTモデルの求人自動作成機能」を開発したビズリーチまで、ChatGPTをビジネスに活用する企業が後を絶ちません。これらの生成AIの応用は、企業がより効率的に運営し、顧客体験を向上させることを実現しています。
一方で、この技術の急速な進展は、ビジネスリーダーに新たな挑戦をもたらしています。それは、既存のビジネスモデルへの適応、新しい市場機会の発掘、そして何よりも、これらの技術を効果的に統合し、競争優位を築く方法を他社よりも早く見出すことです。本記事では、これらの課題に対する洞察と解決策を提供し、読者が生成AIの潜在能力を最大限に活用できるよう支援いたします。

2. ChatGPTの活用オプション
生成AIの世界は、特にChatGPTの登場により、ビジネスに革新的な変革をもたらしています。OpenAIのAPIを活用する際には、いくつかの主要なオプションがあり、それぞれが異なるビジネスニーズに対応します。ここでは、これらのオプションを探り、各々の特徴とビジネスへの応用例を紹介します。
2.1 プラグイン
最もアクセスしやすいオプションは、ChatGPTのプラグインを利用することです。この方法は、技術的な専門知識が限られている状況でも容易に活用可能で、主に標準的な応答や基本的なタスク自動化に適しています。たとえば、レストラン検索・予約サイト「食べログ」は、食べログ掲載店舗のネット予約在庫情報をChatGPTに連携することで、ユーザーがChatGPTを使って飲食店の最新の空席情報を検索できるようにしました。このようにプラグインの機能を活用することで、ウェブサイトやアプリケーションでの顧客サポートの自動化、FAQセクションの動的な応答生成、あるいは基本的なコンテンツ生成ができるようになります。なお、企業がこのプラグインを自社プロダクトやサービス開発に活用するためには、ウェイティングリストへの登録が必要となります。

2.2 プロンプトデザイン
次に、プロンプトデザインを通じたカスタマイズです。「プロンプト」とは、ChatGPTに送る際にチャット欄に入力する質問文章のことです。つまり、「プロンプトデザイン」とは、ChatGPTからの精度高い回答を期待するために、ChatGPTへの質問・命令を特定のタスクに合わせて最適化・デザイン・調整し、より特定のニーズに合わせることを意味します。たとえば、業界特有の用語や特定のビジネスシナリオに対応するために、カスタマイズされたプロンプトやテンプレートを設計するのです。このアプローチは、上述のビズリーチ社の職務経歴書や求人広告の自動作成に活用されている手法で、他にも特定の顧客層へのカスタマイズされたコミュニケーションや定型フォーマットに基づく文書作成などに有効です。

2.3 ライブラリの活用
第三のオプションは、LangChainやLlamaIndexなどのライブラリを活用することです。これらのツールは、特定の機能や自社データベースとの統合を比較的に容易にし、より高度なカスタマイズを実現します。これは「RAG(検索拡張検索)」と呼ばれる技術を利用しており、ChatGPTのようなLLMモデルと外部データを組み合わせて、LLMモデルがまだ学習していないデータをベクトル化し、文脈的意味を容易に捉えられるようにします(非構造化テキストデータの分析時間短縮技術)。LangChainやLlamaIndexなどはこのRAGという技術を活用しやすくするための開発者向けライブラリです。例えば、自社の就業規則を基にしたバーチャル人事質問応答システムの構築や、独自のデータを活用した製品レコメンデーション機能、企業特有のニーズに合わせた情報処理などに利用されます。なお、2023年11月に開催された「OpenAI DevDay」で発表されたGPT-4V APIでは、画像データとテキストデータの両方を取り込むことを実現する「マルチモーダルRAG」が注目され、プロダクト開発の可能性がさらに広がっていくものと思われます。
2.4 ファインチューニング
最後に、ファインチューニングを介した独自モデルの開発です。この方法では、生成AIモデルをコピーし、自社データベースで学習させることにより、特化型のGPT独自モデルを開発します。これにより、特定の業界や用途に特化した言語モデルを自社で開発することが可能になります。このアプローチは、業界固有のニーズに対応した高度なカスタマーサポートシステムや、企業独自の内部ポリシーに準拠したコンテンツ生成などに特に適していますが、一方で、独自のLLMモデルの開発にはデータサイエンティストやAIエンジニアが必要で、開発の難易度・コストが一気に高くなります。
異なるレベルのカスタマイズ性、技術的要件、そして応用の可能性についてご理解いただけましたでしょうか?自社の目的や能力に応じた最適な方法を選択し、生成AIの力を最大限に活用する上で参考にしていただけますと幸いです。
3. ライブラリLlamaIndexを活用した特化型GPT開発
生成AIを活用する上で、LangChainやLlamaIndexのようなライブラリは非常に重要な役割を果たします。この章では、特にLlamaIndexにフォーカスし、その活用方法、特化型GPTの仕組み、およびLlamaIndexを用いた開発の全体像について掘り下げます。

3.1 LlamaIndexの活用方法
LlamaIndexは、生成AIを用いて大量のデータから関連情報を抽出し、特定の問い合わせに対応するためのライブラリです。このライブラリの最大の特長は、膨大な情報源から即座に関連するデータを検索し、それを用いて具体的かつ有益な回答を生成する能力にあります。
3.2 特化型GPTの開発
LlamaIndexは、特化型GPTの開発においても中心的な役割を果たします。特化型GPTとは、特定の業界やビジネスニーズに特化したカスタマイズされた生成AIモデルのことです。LlamaIndexを活用することで、企業は特定の業界用語やプロセスに適応したAIアシスタントを開発することが可能になります。たとえば、医療分野であれば、特定の病状や治療法に関する専門知識を持つAIアシスタントを開発することができ、法律業界では、特定の法律用語や過去の裁判例に基づいてアドバイスを提供するAIを構築することも可能です。また、アフターサービス業界では、顧客からの具体的な問い合わせに対して、製品データベースやFAQから即時に情報を引き出し、タイムリーかつ正確な回答を提供するAIカスタマーサポートを構築することも可能です。
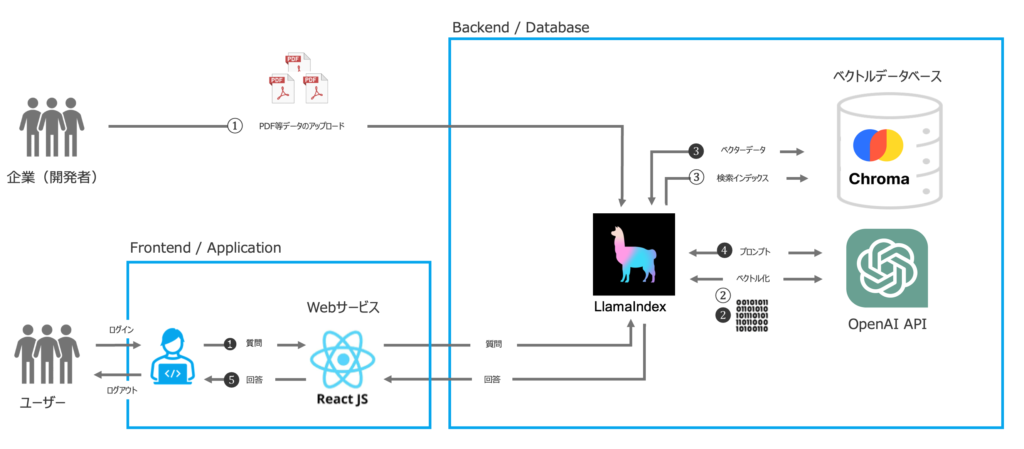
3.3 図解: LlamaIndexを利用した特化型GPTの仕組み
この章の最後には、LlamaIndexを使用した特化型GPTの仕組みの一例を図解で説明します。ライブラリを利用したプロダクトの全体像を把握し、自社で開発を計画する際の参考にしていただければ幸いです。企業が、ユーザーからの質問に対して自社データベース(PDF)を活用して回答を生成するシンプルな特化型GPTを開発することを前提としており、フロントエンドにはReact.jsを、ベクトルデータベースにChromaを利用することを想定しております。ざっくり以下のような処理がされています。
(1)自社データの流れ(一例)
- 自社データPDFをアップロード
- アップロードしたデータをベクトル化しデータベースに保存
- 必要なデータをすぐに取り出せるようにインデックス化
(2)ユーザーからの質問の流れ(一例)
- ユーザーが質問を入力
- 受け取った質問をベクトルデータ化
- データベースの中から最も関連性の高いデータを取得
- 質問データと最も関連性の高いデータを一緒にしてプロンプト
- OpenAI APIが回答を生成
4. OpenAIのデータセキュリティとポリシー
OpenAIが提供する生成AIサービス、特にAPIの使用においては、データセキュリティとプライバシーポリシーが非常に重要です。この章では、OpenAIのデータセキュリティとプライバシーポリシーの主要な側面を詳しく掘り下げます。
4.1 ユーザーデータの取り扱い
OpenAIは、APIを通じて受け取ったユーザーデータを、原則、モデルのトレーニングやサービス改善のためには使用しないというポリシーを持っています。この方針は、ユーザーのプライバシーを尊重し、データの安全性を保護するために重要です。ユーザーデータは、その提供された目的に沿ってのみ使用され、他の目的には利用されません。

4.2 30日間保持ルール
OpenAIは、ユーザーからのデータを最大30日間保持することがありますが、この保持は運用上の必要性やデバッグ、規制遵守のために限定されます。この期間経過後、データは削除されます。このポリシーは、サービス提供の品質を保持するためのものであり、新たなモデルのトレーニングには使用されません。

4.3 ゼロデータ保持(ZDR)ポリシー
ゼロデータ保持(Zero Data Retention)ポリシーは、ユーザーのデータを一切保持しないという方針です。このポリシーは、特にデータのプライバシーが重視されるサービスを開発する場合に、開発者の選択によって適用できる可能性があります。

4.4 データ処理の透明性
OpenAIは、ユーザーデータの処理において透明性を重視しています。この透明性により、ユーザーは自身のデータがどのように使用され、どのようなセキュリティ措置が講じられているかを明確に理解することができます。これには、データ収集、保持、使用に関するポリシーの詳細が含まれ、ユーザーの信頼を確保するために不可欠です。
4.5 その他のデータセキュリティ措置
OpenAIは、データ暗号化、アクセス管理、監査トレイルなど、データセキュリティを確保するための複数の措置を実施しています。これらの措置は、ユーザーデータの安全性を保ち、不正アクセスやデータ漏洩のリスクを最小限に抑えるために重要です。
詳しくはOpenAI社のEnterprise Privacy at OpenAI(英語ページ)をご確認ください。
5. API利用料のリアリティと対策
この章では、OpenAI APIを利用する際のコスト管理と効率化のための戦略に焦点を当てます。
5.1 日本語と英語利用時の料金体系比較
OpenAI APIは、処理をする言語によって異なるトークン数が設定されていることから、言語によってAPIの利用料が大きく異なります。日本語はカウントされるトークン数が多くなる傾向があり、英語と比較してAPIの利用料金が高くなりがちです。例えば、日本語の場合は約1文字あたり1トークンとカウントされますが、英語の場合は約4〜5文字(つまり平均1単語)当たり1トークンとカウントされます。以下の例のとおり、同じ文章を日本語と英語で比較した場合、日本語では326文字(=396トークン)と認識され、英語だと696文字(144トークン)と認識されます。つまり、同じ文章で比較をした場合、英語で利用した場合にはChatGPTの利用料金が約3分の1になります。

5.2 API利用料を減らすための戦略とヒント
日本語をベースにOpenAIのAPIを利用する場合のAPI利用料金が比較的に高くなってしまいます。APIの利用料金を削減するためには、質問->回答によりカウントされるトークン数を軽減する必要があります。ここでは、トークン数を減らすための戦略とヒントについて解説したいと思います。
(1)効率的なプロンプトの設計
具体的かつ簡潔なプロンプトを設計することで、必要とするトークン数を削減できます。また、回答文字数を事前に制限をする等、無駄な情報の排除や情報を必要最小限に抑えることで、トークン数を軽減することが可能です。
(2)モデルの選択
ChatGPTには異なるモデルが存在し、どのモデルを使用するかでコストが変わります。例えば、一般的なプロンプトにはより安価なGPT-3.5を使用し、より複雑な回答の生成にのみGPT-4を使用するなどの工夫をすることで、コストパフォーマンスを高めることが可能です。
(3)バッチ処理
類似のリクエストをまとめて一度に処理することで、APIコールの回数を減らすことができ、それによりAPI利用料を削減することができます。
(4)監視と分析
APIの使用状況を定期的に分析し、最適化の可能性を探ります。使用状況を詳細に分析することで、トークン数の削減が可能な領域を見極め、API利用料を削減するための戦略を練ることが重要です。
6. まとめ
本記事を通じて、生成AI、特にChatGPTのようなツールをビジネスに活用するための戦略的アプローチについて考察しました。これらの技術をいかに活用できるかは、企業にとって競争上の優位性をもたらし、新たな価値を創出できる可能性も広がります。技術の進化に敏感に適応し、倫理的かつセキュアな利用方法を模索しつつ、完璧を目指さずまずは使ってみることが重要です。長期的に見れば、生成AIはビジネスの変革を促し、未来のビジネス風景を形作る鍵になるものと信じています。INDIGITALでは、みなさまの自然言語処理技術を活用したAIプロジェクトの立ち上げからプロトタイプの開発、本開発に至るまで一気通貫でサポートしてまいります。